Delta Lake has become a popular open-source product in data engineering landscape when it comes to modern table formats to power up your data. But is it the right one for your data solution? Lets deep drive a bit to understand.
Well, some of the most common requirements Enterprise Data Architect has to address while architecting data engineering solutions are.
- incremental data processing.
- data versioning.
- efficient data ingestion.
- point in time view of data.
- feed changes from databases into a data platform for long retention and to support analytical queries at scale.
What is Delta Lake?

Delta Lake is one of the hiker’s paradise – beautiful, milky- turquoise-green alpine lake located in Grand Teton National Park. But that a subject for another day, our subject of the day is an open solution that provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing on top of existing data lakes, such as S3, ADLS, GCS, and HDFS.
Delta Lake offers,
- ACID transactions on Spark: Serializable isolation levels ensure that readers never see inconsistent data.
- Scalable metadata handling: Leverages Spark distributed processing power to handle all the metadata for petabyte-scale tables with billions of files at ease.
- Streaming and batch unification: A table in Delta Lake is a batch table as well as a streaming source and sink. Streaming data ingest, batch historic backfill, interactive queries all just work out of the box.
- Schema enforcement: Automatically handles schema variations to prevent insertion of bad records during ingestion.
- Time travel: Data versioning enables rollbacks, full historical audit trails, and reproducible machine learning experiments.
- Upserts and deletes: Supports merge, update and delete operations to enable complex use cases like change-data-capture, slowly-changing-dimension (SCD) operations, streaming upserts, and so on.
- Caching: Because the objects in a Delta table and its log are immutable, cluster nodes can safely cache them on local storage.
- Data layout optimization: automatically optimizes the size of objects in a table and the clustering of data without impacting running queries.
- Audit logging: based on the transaction log.
How Delta works?
- Is a file-based format or to be rather more exact – a table format.
- stores the schema, partitioning information, and other data properties in the same place as the data.
- partition through paths.
- creates a transaction log which maintains a record of all operations requested on data, and the table metadata, as well as pointers to the data files themselves and their statistics.
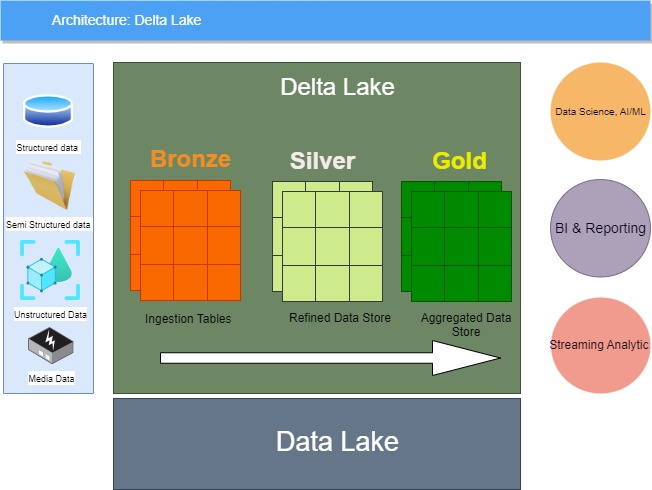
Delta Lake has 3 zones.
- Bronze: massive amounts of raw data come from different sources into this zone.
- Silver: data flows constantly into this zone from bronze zone. Data is cleaned and filtered by the twists and turns of the various functions, filters, and queries, becoming cleaner as it moves.
- Gold: Data is being further cleaned and stringently tested then stored into this zone so that data could be consumed by consumers like BI Reporting, AI/ML etc.
Delta Lakes breaks down any comment to perform action on data using the below list of these actions are:
- Add File
- Remove File
- Update Metadata
- Set Transaction
- Change Protocol
- Commit Info
Conclusion
While adopting delta lake would be the future choice for industry and organization architecture space – it may provide the efficient way to understand organization specific business unit needs or specific group and represents single source of truth without accidental modification, hence we can safely say – it is the golden standard of business unit data and the gateway for accuracy which is always a key input to BU/organization specific AI needs.
Let’s create an accurate data lake that is not only beneficial to increase value to each organization/industry but also increase TCO also.